When AI Crawlers Attack: A Server Performance Horror Story
- tags
- #Devops #Performance #Ai #Gogs #Nginx #Troubleshooting
- published
- reading time
- 5 minutes
How ClaudeBot brought my Gogs server to its knees and taught me about the hidden costs of the AI gold rush
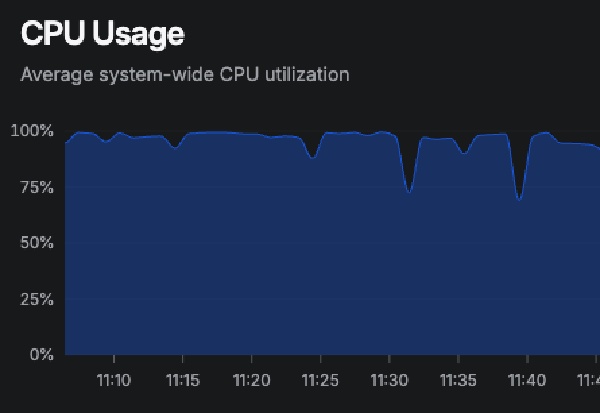
The Problem: Server on Fire
It started like any other morning. My monitoring system, Bezel, was screaming at me: 98% CPU usage on my modest server which wasn’t build for such thing. The server was practically on fire.
A quick top command revealed the culprit: my Gogs git repository service was consuming around 20% CPU constantly. For a service that usually idles at 2-3%, this was alarming. I’d recently migrated from repo.codeskraps.com to git.codeskraps.com, so my first instinct was to blame the domain change.
First Lead: The Domain Migration Red Herring
The initial investigation seemed promising. The systemd logs showed Gogs had consumed an astronomical 1 day, 10 hours, and 57 minutes of CPU time before my reboot. The application logs still showed references to the old domain:
Available on http://repo.codeskraps.com/
Classic configuration mismatch! I updated the app.ini file:
[server]
DOMAIN = git.codeskraps.com
EXTERNAL_URL = http://git.codeskraps.com/
The CPU usage calmed down immediately. Problem solved, right? Wrong.
The Real Culprit Emerges
An hour later, the CPU spiked again. Time to dig deeper.
The database logs revealed a disturbing pattern - constant failed authentication attempts:
record not found
SELECT ... FROM `user` WHERE user.email = "some@email.com" ...
record not found
SELECT ... FROM `user` WHERE user.email = "some_other@email.com" ...
Every few seconds, someone was trying to authenticate with non-existent user accounts. But who? The strace output showed child processes being spawned and terminated rapidly, with heavy database lock contention.
Down the Authentication Rabbit Hole
I suspected compromised credentials or a misconfigured CI/CD system. The email addresses looked like internal corporate accounts - maybe some automated system was trying to access repositories with old credentials?
I spent valuable time investigating:
- Webhook configurations
- Failed delivery queues
- Repository corruption
- Database integrity
- Git process loops
All clean. The mystery deepened.
The Smoking Gun: Web Server Logs
Finally, I checked what I should have looked at first - the nginx access logs:
sudo tail -f /var/log/nginx/access.log | grep git.codeskraps.com
The output was shocking:
216.73.216.179 "GET /codeskraps/ManualTrader/src/..." "ClaudeBot/1.0"
216.73.216.179 "GET /codeskraps/Blog/commits/..." "ClaudeBot/1.0"
216.73.216.179 "GET /codeskraps/sBrowser/commit/..." "ClaudeBot/1.0"
ClaudeBot was absolutely hammering my server. Request after request, hitting every file, every commit, every branch, with different language parameters (?lang=es-ES, ?lang=pt-PT, etc.). Hundreds of requests per minute from Anthropic’s web crawler.
The AI Crawler Problem
Each ClaudeBot request forced Gogs to:
- Process the HTTP request
- Attempt user authentication (explaining the database queries)
- Generate git file/commit views
- Parse and render repository content
- Return potentially large responses
With a relentless stream of requests, my poor single-core server was drowning. The “authentication failures” weren’t failed logins - they were Gogs trying to determine access permissions for each crawled page.
The Solution: Just Say No
The fix was surprisingly simple. I updated my nginx configuration to block ClaudeBot:
server {
server_name git.codeskraps.com;
# Block ClaudeBot to prevent CPU overload
if ($http_user_agent ~* "ClaudeBot") {
return 403;
}
location / {
proxy_pass http://localhost:3000;
# ... rest of config
}
}
Immediate relief. The logs showed ClaudeBot getting 403 Forbidden responses instead of overwhelming my application server:
216.73.216.179 "GET /codeskraps/ManualTrader/..." 403 134 "ClaudeBot/1.0"
CPU usage dropped to normal levels within minutes.
The Broader Issue: AI’s Hidden Infrastructure Cost
This incident highlights a growing problem in the AI era: aggressive web crawling is becoming an infrastructure tax on small developers and businesses.
AI companies are in an arms race to collect training data. Their crawlers are becoming more aggressive, more comprehensive, and more resource-intensive. While large platforms like GitHub can handle the load, small self-hosted services get overwhelmed.
Consider the resources consumed:
- Bandwidth for serving pages that will never be seen by humans
- CPU cycles processing requests that provide no value to the site owner
- Database queries for permission checks on content that will be scraped regardless
- Server costs scaling with crawler activity, not actual usage
What You Can Do
If you’re running your own services, consider these protective measures:
1. Monitor Your Logs
Check your web server logs regularly for crawler patterns:
grep -i "bot\|crawler" /var/log/nginx/access.log | tail -20
2. Implement Selective Blocking
Block aggressive crawlers in your web server configuration:
if ($http_user_agent ~* "(ClaudeBot|GPTBot|ChatGPT-User|CCBot|anthropic|OpenAI)") {
return 403;
}
3. Use robots.txt (Though Many Ignore It)
User-agent: ClaudeBot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
4. Rate Limiting
Implement request rate limiting to prevent any single source from overwhelming your server.
The Irony
The most ironic part? I was using Claude (Anthropic’s AI) to debug the very problem that ClaudeBot (Anthropic’s crawler) was causing. It’s a perfect metaphor for the AI age - the same companies creating useful AI tools are also creating the infrastructure problems we need AI tools to solve.
Conclusion
This wasn’t a complex technical issue requiring deep system knowledge. It was a resource exhaustion problem caused by an overly aggressive web crawler. The time I spent investigating authentication systems, database corruption, and git processes was wasted because I didn’t start with the most basic question: “What’s actually hitting my server?”
The lesson? When facing performance issues, always check your access logs first. And in 2025, be prepared to defend your servers against the AI crawler invasion.
Your personal server wasn’t designed to feed the AI training pipeline. It’s okay to say no.
Want to protect your own services? Start with web server logs and don’t let the bots eat your lunch.